Als we ophouden met elke ongewenste gebeurtenis een crisis te noemen, ontstaat er ruimte voor nieuwe benaderingen van incidenten die beter recht doen aan wat er daadwerkelijk gebeurt. Zo vragen disrupties om een disruptiemanagement dat past bij de dynamiek van dergelijke verstoringen. Dat geldt zeker voor (productie)bedrijven en uitvoeringsorganisaties. In dit blog beschrijf ik de eerste beginselen van disruptiemanagement. Wie weet komen er nog meer.
Het grote verschil tussen een emergency en een disruptie is de verschijningsvorm. Bij emergencies is er eigenlijk altijd sprake van acuut en spoedeisend ingrijpen op een fysiek zichtbaar incident. Dat openbaart zich meestal in de vorm van een flitsramp; eerst was er niets, en toen was er (in een flits) de brand, de crash of de instorting.

Dat dit overigens niet helemaal klopt laat de incubatieperiode van Turner zien. Volgens hem dienen sommige rampen zich al veel langer van tevoren aan, maar worden de signalen niet gezien of verkeerd geïnterpreteerd. Wat Turner beschrijft heeft in zekere zin de karakteristiek van een dreiging, zoals ik betoog in de kleine taxonomie van de ongewenste gebeurtenis. Het wordt echter alsnog een emergency door een situational awareness niveau nul van de verantwoordelijke partijen, waardoor er niet proactief ingegrepen werd.
Het flitsincident wordt naar analogie van de kleine taxonomie logischerwijze opgevolgd door de flitsdisruptie en / of de flitscrisis. Van oudsher zijn calamiteitenorganisaties op die leest geschoeid, waarbij het bestrijden van de emergency voorop staat. In verhouding is de spoedeisende hulpverlening normaliter veel groter dan de disruptie en de crisis. Daardoor is van oudsher onvoldoende beseft dat in een flitsincident al de kiemen van die twee andere incidentvormen verstopt zitten.
Multipliciteit
Weliswaar werd er soms gesproken over de ramp na de ramp, maar dat bleef toch vooral beperkt tot een seriële incidentopvatting. Er was niet onopgemerkt gebleven dat in sommige gevallen, zoals de Bijlmerramp, ook in de nazorgfase nog bijzonder veel viel te regelen en op te lossen. Misschien nog wel meer (en in ieder geval langer) dan het initiële optreden van de hulpverleningsdiensten na de crash. Toch bleef het incidentframe van de Bijlmerramp een neergestort vliegtuig, zonder de ellenlange naturalisatierijen en huisvestingsproblemen die er ontstonden.
Met het idioom van de fundamental surprise en de taxonomie van de ongewenste gebeurtenis zou ik de Bijlmerramp nu niet meer typeren als een ramp die gevolgd werd door een lange nazorgfase. Eerder zou ik zeggen dat er sprake was van een al langer lopende sociale huisvesting- en migrantencrisis die zichtbaar werd door een vliegtuigcrash in bewoond gebied. Voor korte tijd werden het minimaal twee interacterende incidenten die zich in een unieke multipliciteit voordeden als één ramp.
De opvatting dat een ongewenste gebeurtenis een multipliciteit is waarin tegelijkertijd vier verschijningsvormen kunnen huizen is nog betrekkelijk nieuw. Het geeft aanknopingspunten (en woorden) om het crisismanagement verder te expliciteren en nuanceren. Als we ophouden met alles crisis te noemen, kom je tot heel andere inzichten en werkwijzen en mogelijk ook tot een effectievere respons.
Disruptiemanagement
De noodzaak van zo’n grammatica voor ongewenste gebeurtenissen komt niet uit de lucht vallen. Veranderingen in de samenleving, zoals andere manieren van productie en logistiek, hebben tot nieuwe incidentvormen geleid. Door verstoringen in supply chains en co-makership zijn veel bedrijven er bijvoorbeeld hardhandig achter gekomen dat er ook nog zoiets bestaat als disruptie en disruptiemanagement. Een verstoring in je bedrijfsvoering zonder brand, explosie of instorting en dus ook zonder hulpdiensten. Maar wie lost het dan op? Dat is wat in het disruptiemanagement geregeld moet worden.

Disrupties kennen hun eigen dynamiek, die deels afwijken van emergency response. Disruptiemanagement kent een aantal beginselen:
- Weak signals, hard response
- Veilig voortzetten
- Houd kleine incidenten klein
Dat vraagt om een proactieve instelling. Wacht niet met opschalen tot er een incident is, maar als er een incident dreigt. Je verschuift de incidentdefinitie dus naar links in de keten. Niet pas aan de bak als het proces stokt, maar als er signalen zijn dat de boel gaat ontsporen. Noem het maar proactieve response: er zijn weak signals voor een bottleneck gedetecteerd, de harde respons is opschaling met de Dikke BOB. Snel situatie inschatten en scenario opstellen, gevolgd door het nemen van beheersingsmaatregelen en / of verder opschalen.
Wat betekent dit in de praktijk? Ten eerste dat er veel meer incidenten zullen zijn. Maar omdat je er snel bij ben, zullen de meesten ervan klein blijven en dus geen majeure disruptie veroorzaken. Dat is het principe van kleine incidenten klein houden: voorkomen van een onbeheersbare situatie.
Continuum
Ten tweede heb je minder mensen nodig in je eerste opschaling. Je hoeft niet heel dik uit te pakken met een groot team en alle rollen en bureaucratie die daar bij komt kijken. Er is een klein slagvaardig team op dienst dat gewoon zijn normale operationele werk doet en bij elkaar komt als het nodig is. Incidenten worden dan dus onderdeel van de normale bedrijfsvoering. Er ontstaat een continuüm tussen volledig operationeel en volledig stilgelegd. De dichotomie van OK en niet OK, die van gewenste- en ongewenste gebeurtenis verdwijnt.
Er kleven ook risico’s aan de opvatting dat incidenten meer een status van een proces dan een gebeurtenis zijn. Die liggen vooral op het vlak van de situational awareness. Je moet de weak signals niet alleen zien en begrijpen, je moet de hard response ook durven doen. Hier betreden we het veld van Kahneman’s human bias. De organisatie moet hulpmiddelen installeren die de besluitvorming onder tijdsdruk ondersteunen en mensen helpt om geen foute beslissingen te nemen.

Om een sluipende disruptie te voorkomen kun je bijvoorbeeld automatische opschalingsniveaus verbinden aan het aantal deelnemers in je responseteams. Ook aan de tijdsduur van de bestrijding kun je automatische maatregelen koppelen. Dus stel dat je initiële team uit drie mensen bestaat bij het niveau ‘klein’, wordt het automatisch niveau middel als er meer dan vijf teamleden zijn. Op dezelfde manier wordt het automatisch niveau ‘middel’ als er langer dan een uur gewerkt is aan het bestrijden van de disruptie.
Incidentpatroon
Op de lange duur verandert daarmee je incident patroon. Het aantal kleine incidenten zal toenemen en waarschijnlijk ook het aantal middel incidenten, omdat je de plafond voor opschaling verlaagd. Je gaat niet zitten wachten op een probleem dat je pas daarna gaat oplossen. Je bent het probleem voor, waardoor het niet meer zal ontstaan. Incidenten krijgen daarmee een andere definitie.
Hiermee normaliseer je verstoringen in je standaard bedrijfsvoering. Het is onderdeel van de basis vakbekwaamheid waar je geen specialisten voor nodig hebt, maar wel opleiding, training en oefening. Dat is wat ik onder veilig voortzetten schaar. Op een veilige manier blijven produceren door het vroegtijdig nemen van extra maatregelen die passen bij de status van je proces.
Naar verwachting zal het aantal grote disrupties dan afnemen onder gelijkblijvende omstandigheden. Maar de disruptie potentie blijft, die is onlosmakelijk verbonden met de keuzes in je productieproces. Dus voorbereiden op majeure ellende blijft noodzakelijk, maar die gaat er dus heel anders uit zien dan vroeger.
Wat overigens onverlet laat dat de flitsdisruptie als gevolg van een flitsramp, al dan niet als crisis aangeduid, nog steeds een realistisch scenario is. Disruptiemanagement is dan ook niet een fenomeen dat de plaats inneemt van iets anders, het komt er bij, on top of. Wen er maar aan.
Update 12 mei 2023: Stoplicht in je hockeystick
De afgelopen drie jaar ben ik druk bezig geweest om deze beginselen van disruptiemanagement verder uit te werken in de praktijk. Een belangrijke inspiratiebron daarbij was de definitie van veerkracht zoals Sidney Dekker die gebruikt. Die hebben we ietwat getweakt op basis van de ervaringen in de praktijk.
Veerkracht kent nu vier elementen:
- Weten waar de grenzen van je bedrijfsvoering liggen
- Zien dat je erover heen gaat
- De middelen hebben om terug te sturen
- En het dan ook doen
Dat laatste punt is vooral van belang als de disruptie nog in een incubatieperiode zit en er nog niet zichtbaar iets mis gaat; als de hockeystick nog in zijn zacht kabbelende fase zit en velen vinden dat er geen reden tot ingrijpen is. Hoe houd je dan je rug recht?
Welnu, door een systeem te maken met duidelijke grenswaarden en alertering. Een stoplicht in je hockeystick. Niet meer op basis van je persoonlijke ervaring, maar op basis van geobjectiveerde normen.
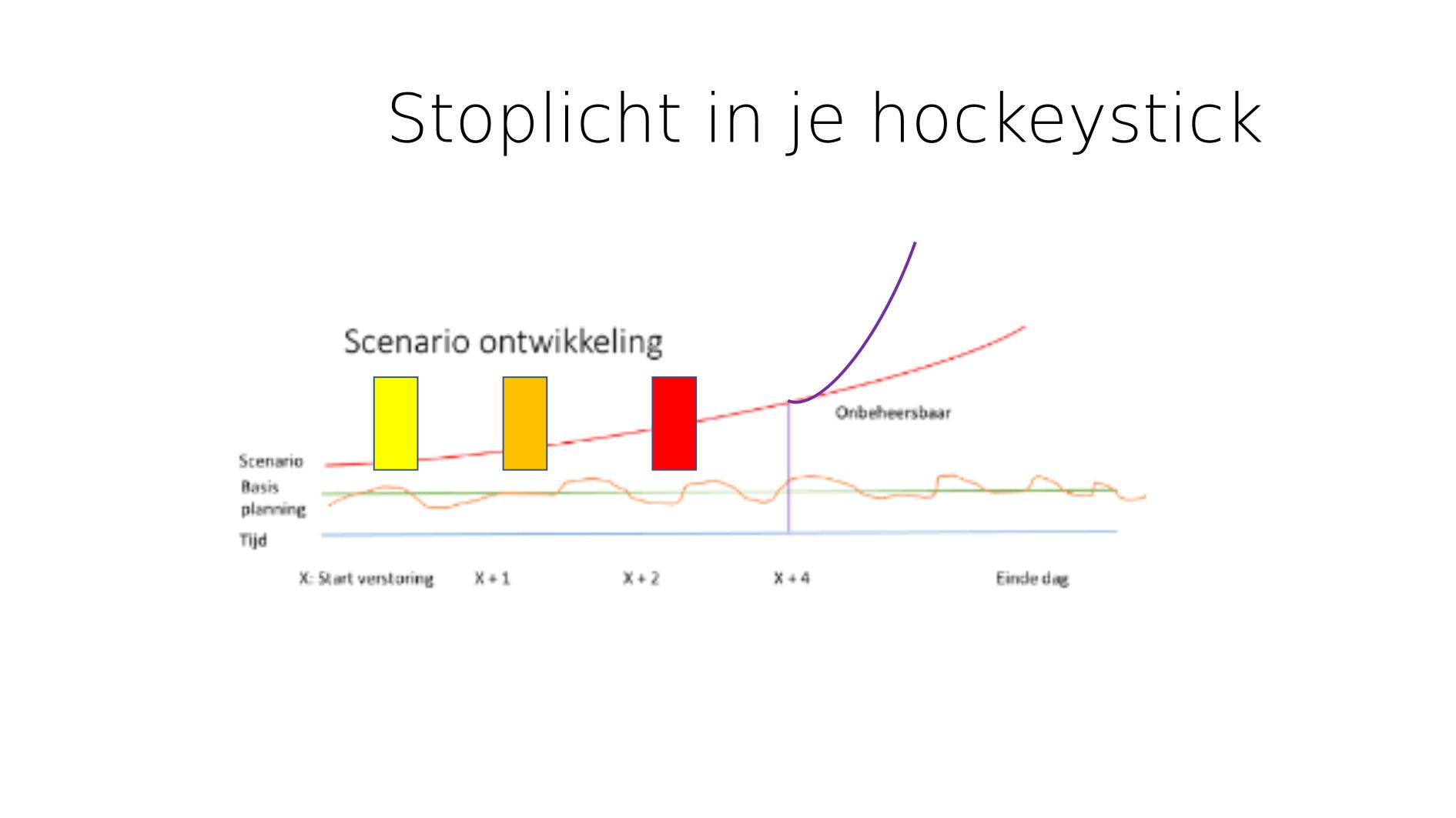
Daarmee definieer je een incident (zonder schade) voordat het een incident met schade wordt. Je gaat proactief opschalen in een proces dat we verzwaarde bedrijfsvoering noemen.
Neem doorlooptijd van je proces als voorbeeld. Dan definieer je code geel bijvoorbeeld als het 15 minuten langer duurt dan normaal, oranje voor een half uur en rood voor een uur.
Op code geel komen de teamleads bij elkaar. Ze hebben de verlengde doorlooptijd gezien (situation awareness level 1) en gaan met elkaar uitzoeken wat er aan de hand is. Als ze daarachter zijn begrijpen ze de situatie (SA Level 2) en projecteren dat voorwaarts.
Wat kunnen we vandaag nog verwachten, wat voor weer is het, zijn er bijzonderheden, enzovoorts. Iedereen zal voor zijn eigen processen daar specifieke vragen voor moeten opstellen. Dan zit je op SA Level 3 en kun je een beargumenteerd besluit nemen.
Een belangrijk onderdeel van deze proactieve opschaling is communicatie. Daarmee zorg je voor een shared situational awareness die de organisatie veel responsiever en alerter maakt, omdat de kennis over de status van je systeem zich niet beperkt tot een paar leidinggevenden.
We maken bij het communiceren onderscheid in informeren, consulteren en alarmeren, afhankelijk van de doelen die de organisatie stelt. Grofweg gezegd: op de hoogte brengen, bevragen of in stelling brengen. Opschalen dus. En dat zal voor elk bedrijf dus anders zijn.
Maar het principe erachter niet: een stoplicht in je hockeystick. Ook die hoort bij de beginselen van disruptiemanagement.
Dit is het vijfde blog in een serie over disruptiemanagement. Eerdere blogs vind je hieronder:
- Kleine taxonomie van de ongewenste gebeurtenis
- Dikke BOB is voor Disruptie
- De zes B’s van de Dikke BOB
- De ellende van complicatie- en escalatiefactoren
- Beginselen van disruptiemanagement
- Beeldvorming trainen voor de Dikke BOB
- De onderstroom van crisis
- De VUCA vinklijst voor disruptie en crisis
- Kwetsbaarheidsanalyse met de Rumsfeld Matrix
Beste Ed, je conclusie dat de shift van emergency response naar disruptiemanagement leidt tot meer incidenten die kleiner blijven kon ik zelf niet helemaal dichtredeneren. Ook dat in een eerder stadium van de ontwikkeling van een incident minder mensen en minder bureaucratie nodig waren kon ik niet helemaal volgen. Het zal best gelden in sommige systemen. Maar wat me met name aan het denken zette waren de voorbeelden Bijlmerramp en explosie bij Marbon. Dat zijn hele goede voorbeelden van problemen die niet zo simpel eerder (voor het incident) op te lossen waren: de sociale huisvesting- en migrantencrisis of het gebrek aan een stevig milieuvergunningensysteem lijken me minstens zo complex als de incidenten zelf. Ik denk dan je in de praktijk inderdaad vooral aanloopt tegen het dilemma welke weak signals toch vragen om een harde response. Blijkbaar vinden wij mensen het bij dergelijke weak signals verleidelijk om het nog maar even aan te zien en dus geen harde response te geven. Hoe had je ook moeten weten dat je de Bijlmerramp ging voorkomen? Ik ga er in ieder geval nog eens even over nadenken, interessant is het zeker!
Ha Dick, dank voor je reactie. Het denken over het onderscheid tussen emergency en disruptie als twee separate entiteiten is nog kakelvers. Er moet dus nog van alles aan getweakt worden. Dan is het mooi als er discussies komen die vragen om de begrippen iets verder uit te diepen.
Wat je eerste vraag betreft, het is niet zozeer dat er een shift van emergency naar disruptie plaats vind. In principe is de verschijningskans van emergencies een zelfstandige variabele die niet beinvloedt wordt door het ontstaan van disrupties. Eerder is het andersom: disrupties worden veroorzaakt door emergencies, of dat nu branden zijn dan wel IT storingen of waterleidingbreuken: er zit mogelijk altijd een disruptie verstopt in een emergency. Waarom ik verwacht dat het aantal disrupties toeneemt is omdat ik voorstel het al in een vroeger stadium dan nu als disruptie te betitelen. En dat wordt dan weer veroorzaakt door de wetenschap van de hockeystick: vroeg opschalen en nagaan of er kans is op ontsporing en daar snel op anticiperen leidt tot meer incidenten. En omdat dergelijke kleine incidenten nog echt klein zijn, hoef je niet op te schalen met grote teams. Je hebt dus minder mensen nodig, alleen de hoofdprocessen. Geen informatiemanagement of andere ondersteunende processen, gewoon eerst BOBBEN met de kernbezetting.
Wat je andere opmerking over de Bijlmerramp betreft, wat daar speelt is dat de crash de onderliggende migratiecrisis zichtbaar maakte. Die zat echter wel verstopt in de crash en de instorting en manifesteerde zichzelf uiteindelijk midden in de rampenbestrijding. Mijn pleidooi is dat in de beeldvormingsfase al gezocht moet worden naar dergelijke verstopte incidenten en crises. Daarom is plaatselijke bekendheid zo belangrijk. Pas als je weet wat er speelt, ben je in staat om de crisis te zien die onder de emergency response schuilt. Hoe vroeger je begint met het aanpakken van die verstopte crisis, hoe beter beheersbaar hij blijft. Maar voorkomen kan je hem denk ik niet. Daar ga ik ook nog eens over nadenken.
Goede analyse en behartenswaardige adviezen. Nu bedenken hoe om te zetten in de praktijk.