De veiligheidsrisico’s bij stedelijke verdichting nemen toe, zo blijkt uit een klein gedachtenexperiment over de voorgenomen uitbreiding van Amsterdam met 20.000 woningen. Maar het grootste risico is misschien wel dat het systeem ‘stad’ fragiel wordt en daarmee gevoelig raakt voor een predictable surprise.
Amsterdam
Twaalf jaar, zo lang heb ik uiteindelijk in Amsterdam gewoond. Van 1993 tot 2005, het grootste deel van die tijd werkte ik voor de brandweer aldaar. Het waren vormende jaren, die goed van pas kwamen toen ik uiteindelijk naar Schiphol overstapte. Waar ik nu nog steeds werk.
In die periode zag ik het geleidelijk aan steeds voller worden in de stad, tot het eigenlijk net te druk werd. Ik woonde in het Oostelijke Havengebied en toen de buurten er omheen ontdekten dat het grasveld aan het water en voor mijn deur zich prima leende als zwembadveldje, was het in de zomer nooit meer rustig. Avond aan avond was er feest en herrie. Als ik de kranten mag geloven is dat nog niet voorbij. Zelfs Douwe Bob bemoeide zich er mee.

Het zijn de normale taferelen van de grote stad, zo zei men tegen mij. Al helemaal in de gebieden met een hoge stedelijke verdichting. Mensen hebben er geen tuintjes of een buiten en maken gebruik van de voorzieningen die de openbare ruimte biedt. Dat leidt onherroepelijk tot spanningen in een wijk. Zeker als de bewonersgroepen nogal van elkaar verschillen en er hun eigen leefgewoontes op na houden, zonder rekening te houden met anderen.
In een samenleving waar de eigen identiteit en vrijheid breed uitgemeten en gevierd wordt, zoals Hans Boutellier schreef in Het nieuwe Westen, nemen die spanningen alleen maar verder toe. In de krant van 4 februari las ik over een voetbalkooi in Oud West, dat gehalveerd dreigde te worden omdat omwonenden geklaagd hadden over de geluidsoverlast. Dat lieten de ouders niet op zich zitten en in een paar weken tijd waren de gemoederen zo verhit dat beide groepen in staat van oorlog met elkaar verkeerden.
Om een voetbalveldje.
Stedelijke verdichting
Dat worden interessante tijden, dacht ik dus ook toen ik las dat Amsterdam tot 2035 maar liefst 20.000 woningen wil bouwen binnen de gemeentegrens. Bovenop de bestaande woningvoorraad van zo’n 450.000 stuks. Welke veiligheidsrisico’s brengt die stedelijke verdichting met zich mee, zo vroeg ik me af.
Aldus maakte ik deze kleine analyse. Niet om tegen stedelijke verdichting te zijn, iedereen moet tenslotte wonen, maar wel om duidelijk te maken dat die verdichting consequenties heeft. Met die consequenties moet je wat doen, dat kan je niet alleen maar aan de bewoners overlaten.
Inmiddels weet ik namelijk dat de overheid wel vaker hals over kop plannen maakt, die bij iets langer nadenken helemaal niet haalbaar zijn. Dat kan je dus al weten voordat je er mee begint en dan hoef je je dus ook niet te verstoppen achter het Met-de-kennis-van-nu-syndroom.
Kijk bijvoorbeeld naar de elektrificatie van onze energiebronnen. Alles moet op het stopcontact, alleen zit het stroomnet bommetje vol. Er kan voorlopig niks meer bij, totdat over vele jaren de netten weer wat zijn opgeplust. Tot die tijd staan op sommige industrieterreinen de dieselaggregaten te stampen om de bedrijven van stroom te voorzien. Tja.

Dat zou met deze stedelijke verdichting niet zo hoeven gaan als je vooraf een analyse maakt. Waar hebben we dan allemaal rekening mee te houden?
Ik vogelde het uit op de achterkant van een bierviltje.
Taxonomie van ongewenste gebeurtenissen
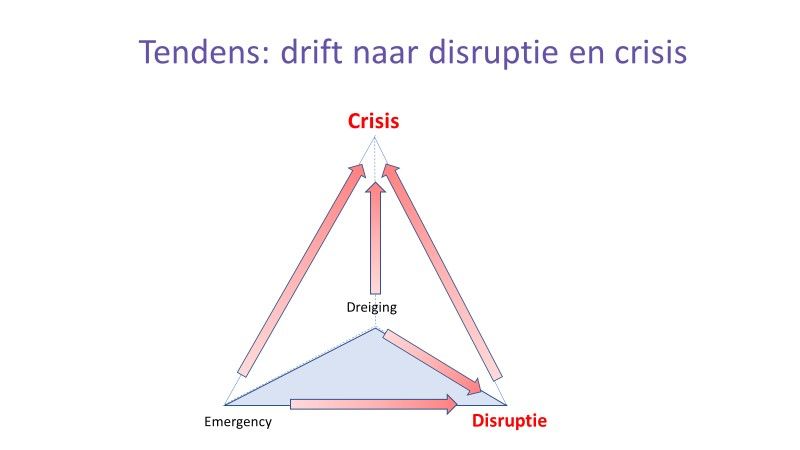
Daartoe besloot ik eerst mijn definities uit de kleine taxonomie van ongewenste gebeurtenissen er bij te pakken. Voor dit blog beperk ik me dan voornamelijk tot emergencies en disrupties. Dreiging, crisis en polycrisis laat ik er even buiten. Nou ja, misschien een beetje crisis dan.
Een emergency of noodgeval is een situatie met onverwacht en acuut gevaar voor levens en/of grote schade die zo snel mogelijk beheerst moet worden;
Een disruptie is een situatie waarin een sociaal systeem (gemeenschap, organisatie, beleidssector, land) een urgente bedreiging van fundamentele waarden en structuren ervaart, waarbij grote onzekerheid speelt en waarin het nemen van verreikende besluiten nodig wordt geacht;
Crisis is een situatie waarin het vertrouwen van een bevoegd gezag of overheidsinstantie zodanig is verzwakt dat ze geen draagvlak meer heeft om een gecompliceerde disruptie dan wel wicked problems op te lossen.
In de praktijk beïnvloeden emergencies, disrupties en crises elkaar. Net als in andere complexe systemen zitten er ontelbare feedback- en feedforwardloops in, die om het even welke op zichzelf staande gebeurtenis koppelt aan eerdere gebeurtenissen, risicoperceptie, framing en schuldigen. Of niet. Dat is de onvoorspelbaarheid uit VUCA (Volatile, Uncertain, Complex, Ambiguous).
Die complexiteitsexercitie ga ik hier niet maken, het was immers op een bierviltje. Wel som ik een aantal voorzienbare veiligheidsrisico’s van stedelijke verdichting op. Niet uitputtend natuurlijk. Het is allemaal bedoeld ter illustratie.
Emergencies & criminaliteit
Bij stedelijke verdichting zal de frequentie van incidenten toenemen. Er zijn immers meer mensen en dat betekent meer hommeles. Dus meer branden, meer verkeersongevallen, meer lekkages van gevaarlijke stoffen en milieuverontreiniging. Meer mensen die van de trap vallen, een hartaanval krijgen of struikelen over stoepranden.

Misschien neemt het aantal omgevallen bomen wel af. Want die moeten natuurlijk plaatsmaken. In ruil daarvoor krijgen we meer plaagdieren. Als er geen buiten is, gaan ze naar binnen.
Ook de criminaliteit zal toenemen. Meer explosieven aan voordeuren; dat waren er in Amsterdam 91 in 2023 en 127 in 2022. Die hangen samen met steeds meer cocainegebruik en -handel. Wellicht ook meer drugslabs in woonwijken, afpersing, vechtpartijen en oplichting.
Meer (kinder)mishandeling.
Daarnaast zal de onrust tussen groepen in wijken toenemen, zoals we nu trouwens ook al zien. Ik noemde slechts twee voorbeeldjes, over het voetbalveldje en het informele zwembad, maar in de praktijk zijn dat er natuurlijk veel meer.
De omvang van incidenten zal ook toenemen. Woningen staan dichter op elkaar, dus er zullen meer mensen last hebben van de rook bij brand. De te evacueren groep wordt groter, net als de behoefte aan noodopvang. En dan gaan we er maar even vanuit dat de brandpreventie wel op orde is en de branden zelf dus niet makkelijk uitbreiden en overslaan. Wat er van preventieve voorzieningen overblijft bij intensief gebruik laten we maar even voor wat het is.
Escalatie van incidenten zal ook toenemen bij stedelijke verdichting. Deels door samenloop, dus meerdere incidenten tegelijk. Maar ook door grotere groepen op straat, meer agressie onderling als wel tegen hulpverleners en het koppelen van belangen: partijen die nooit samenwerken en elkaar opeens vinden in het tegen zijn.
Samen tegenwerken.
Disrupties & verstoringen
Denk ook aan ‘feesten’ als Koningsdag, Oud & Nieuw, evenementen, bijeenkomsten, activisten en demonstraties. Daar weten we inmiddels van dat die flink uit de klauw kunnen lopen.
Al deze incidenten zullen naast hun primaire schade ook veel secundaire schade toebrengen aan de verdichte stad. Er is immers minder ruimte, minder redundantie om ellende op te vangen of om te leiden. Weer niet bedoeld als volledig, maar wel ter indicatie een kleine greep secundaire veiligheidsrisico’s bij stedelijke verdichting:

Verkeersopstoppingen en omleidingen: Het afsluiten van wegen of straten om ruimte te maken voor hulpdiensten kan leiden tot verkeersopstoppingen en omleidingen in omliggende gebieden. Dit verstoort het normale verkeer in de stad en belemmert de mobiliteit van bewoners, werknemers en bezoekers. Het zal sowieso bij een verdichte stad al moeilijker zijn om goed bij de plaats incident te komen. Toen ik nog bij de brandweer Amsterdam reden we aan van drie kanten in de binnenstad.
Onderbreking van openbaar vervoer: Incidenten kunnen leiden tot de tijdelijke stopzetting of wijziging van openbaar vervoersdiensten, zoals bussen, trams, metro’s of treinen. Dit beïnvloedt de bereikbaarheid van verschillende delen van de stad en verstoort het dagelijks leven van mensen. Hoe groter de verdichting, hoe meer mensen vastlopen en niet meer weg kunnen.
Evacuaties en tijdelijke huisvesting: In geval van ernstige incidenten kan het nodig zijn om gebieden te evacueren en bewoners tijdelijk elders onder te brengen, bijvoorbeeld in opvangcentra of bij familie en vrienden. Dat zijn er in een verdichte stad meer, kijk maar naar wat er bijvoorbeeld gebeurde bij de explosie in Rotterdam op het Schammenkamp. Een typisch voorbeeld van veiligheidsrisico’s bij stedelijke verdichting.
Impact op bedrijven en economische activiteit: Afgezette wegen en beperkte toegang tot bepaalde gebieden zullen bedrijven beïnvloeden, bijvoorbeeld door het verminderen van klantenstromen, het verstoren van leveringen en het belemmeren van werknemers om op het werk te komen.
Infrastructuur
Deze categorieën disrupties volgen uit incidenten en emergencies. Maar er zijn ook verstoringen die te maken hebben met overbelasting van (nuts)voorzieningen en falende (kritieke) infrastructuur. Om er maar een paar te noemen:
- De vraag naar elektriciteit groeit. Kan het stroomnet dat aan? Hoeveel redundantie zit er uiteindelijk in het systeem? Kan er gecompartimenteerd worden of valt gelijk de hele boel uit?
- Er zal meer drinkwater nodig zijn. En dat is er nu al te weinig, geven de drinkwaterbedrijven aan.
- Kan de riolering het aan? De stadsverwarming? Communicatienetwerken?
- Zijn de vervoerssystemen ingericht op de stedelijke verdichting?
Hoe dan ook, als dit soort infrastructuur uitvalt zullen de effecten door de stedelijke verdichting altijd toenemen. En dan heb ik het nog niet eens gehad over sociale spanningen en onrust in wijken die toeneemt als de bevolkingsdichtheid stijgt.
Maar er is nog iets, en dat besprak ik al eens in dit blog over de complexiteitsprincipes van Casti.
Je moet namelijk de bovenstaande opsomming faalkansen niet zien als op zichzelf staande gebeurtenissen, maar als kenmerken van een complex systeem. Ze hebben met elkaar te maken. Mensen zullen ze met elkaar verbinden, van losse gevallen een reeks of een trend maken, betekenis geven die er misschien niet is (maar dan dus wel).
Complexiteitskloof
Ze zullen het framen, cancellen, boycotten en complotten. Op zoek gaan naar de schuldige. Voor je het weet heb je een crisis en een verzwakt bestuur.

In systeemtermen neemt de complexiteit van het bestuurde systeem dus toe, zou Casti zeggen, onder verwijzing naar de wet van de vereiste variëteit. Het komt er in het kort op neer dat het besturende systeem meer vrijheidsgraden moet hebben dan het systeem dat bestuurd wordt. Deze wet staat ook bekend als de wet van Ashby.
Een systeem kan alleen voortbestaan wanneer het dezelfde of meer variatie heeft als zijn omgeving
wet van ashby
Als het besturende systeem niet mee ontwikkelt met de complexiteit van het bestuurde systeem, zal de complexiteitskloof groeien en de fragiliteit van het totale systeem toenemen. Het komt dan in een situatie die Bazerman in dit blog omschreef als een predictable surprise. Je kunt niet voorspellen wat en wanneer er iets grandioos mis gaat, maar wel dat het niet vreemd is dat er zoiets gebeurt.
En ja, geluk en pech spelen hierin ook een grote rol. Maar alleen omdat het een wankel systeem is geworden waar de veerkracht uit is verdwenen.
Er is gelukkig wel wat aan te doen: de opties en variëteit van het besturende systeem vergroten. Door meer hulpdiensten, betere opleidingen, dikkere infra met meer redundantie, onderhoud op orde, projecten in de wijk, gezondheidszorg en jeugdzorg verbeteren. Om maar wat te noemen.
Van Sidney Dekker leen ik zijn definitie van veerkracht: je moet de grenzen kennen van je bedrijfsvoering (stad), weten wanneer je er overheen gaat en de middelen hebben om terug te sturen.
Ik voeg daar uit mijn eigen praktijk aan toe: en dan moet je het ook nog doen. Dat laatste blijkt altijd het meest lastig.